

The main analytic sample consisted of n = 3,142 adult individuals from the CHRIS study with available metabolomics and proteomics data. The AbsoluteIDQ® p180 kit from Biocrates (Biocrates Life Sciences AG, Innsbruck, Austria) was used for metabolite quantification in fasting serum samples16. The high abundance plasma proteome was determined using the Scanning SWATH mass spectrometry-based approach17. We first present the study sample’s main characteristics by health status (any morbidity vs. healthy) and the relationships between the co-occurring comorbidities. Next, we provide findings from the random forest (RF) analysis, which was complemented by multiple linear regression analyses to better evaluate actual differences in abundances of each significant metabolite and protein from the RF analysis by health status, independent of age and sex. Finally, we investigated associations between organ specific morbidity and all available metabolites and proteins using linear regression models.
Health status and characteristics of the study sample
The characteristics for the main analytic sample are presented in Table 1. The CIRS organ domains most completely described by the available data (completeness ≥ 50%) were the hypertension, cardiac, respiratory, neurological, renal, vascular, endocrine-metabolic, hepatic and psychiatric/behavioral domains (Table 1). The remaining domains had < 50% completeness and in general a lower proportion of unhealthy individuals was observed for these domains (Table 1). Among all individuals, 56% (n = 1,751) were affected by at least one morbidity condition (CMI ≥ 1). As expected, these were on average older than healthy individuals (CMI = 0; Table 1; Fig. 1). The top five organ domains affected by health problems were the hepatic, vascular, hypertension, endocrine-metabolic and the respiratory domain, with 27.4%, 14.9%, 12.8%, 10.3%, and 8.8% of morbidity prevalence estimates, respectively. We additionally provide the characteristics for the CHRIS cohort, regardless of available omics data, to confirm the robustness of main characteristics and estimated disease prevalences in our analytic sample. These are reported in Supplementary Table S1 and Figure S1.

Distribution of health status and age in the main analytic sample. (A) Age distribution (y-axis) by Comorbidity Index values, which range from 0–9 (x-axis). The x-axis additionally provides information on the total number of participants with each corresponding index value. The Comorbidity Index value expresses the total number of CIRS organ domains scoring ≥ 2. (B) Absolute distribution of “Any morbidity” (no, yes) by age group. Red bars represent the number of participants with any morbidity in the respective age group, whereas the number of healthy subjects is shown in blue in this stacked bar plot (C) Age distribution by morbidity conditions (no, yes) in the specific CIRS domains.
Next, we explored relationships between the 14 CIRS domains through ordinary correspondence analysis (OCA; Fig. 2), for which information was encoded as a binary variable in the analysis (no morbidity, morbidity). We observed proximity between the hypertension, renal and endocrine domains, the cardiac and the vascular domains, and between the neurological and the psychiatric domains. To compare the robustness of the comorbidity relationships we present the OCA analysis results for the CHRIS cohort in Supplementary Figure S2.

Biplot of ordinary correspondence analysis presenting relations between the 14 CIRS domains. Information on each domain was encoded as a binary variable (no morbidity, morbidity). Each data points represents one individual. CIRS domains with a stronger relation have longer (size consistency) and closer (direction consistency) loadings.
Multi omics signatures of health status
To avoid confounding of results due to the impact of medication17, we performed the analysis on metabolite and protein abundances adjusted for use of medications that were not considered in the CIRS definition (Supplementary Table S2).
For the RF analysis we built a model including age, sex, 174 metabolites and 148 proteins as predictors. Overall, NModel = 100 RF models were generated, each containing NTree = 500 trees per model, using repeated random subsampling with 80% training and 20% validation set sizes, respectively. We compared the performance measures using the area under the receiver operating curve (ROC AUC), as well as the Matthew’s correlation coefficient (MCC) and MCC-F1. The RF model showed moderate performance (AUC = 0.747, 95% Confidence Interval (CI) = 0.743, 0.751; Fig. 3; MCC and MCC-F1 are presented in Supplementary Figure S3). In addition, we built models that included varying sets of the predictors, which were (a) age and sex, (b) age, sex and metabolites, (c) age, sex and proteins, and (d) age, sex, metabolites, proteins. When comparing differences in mean AUCs and mean MCCs, the metabolomics/proteomics-based models (b, c,d) generally showed greater performance over the model including age and sex only.When comparing the different omics-based models, statistically significant differences in performance were found, but these differences were not robust across the two performance measures AUC and MCC. A detailed performance comparison of these models is presented in Supplementary Text S1.
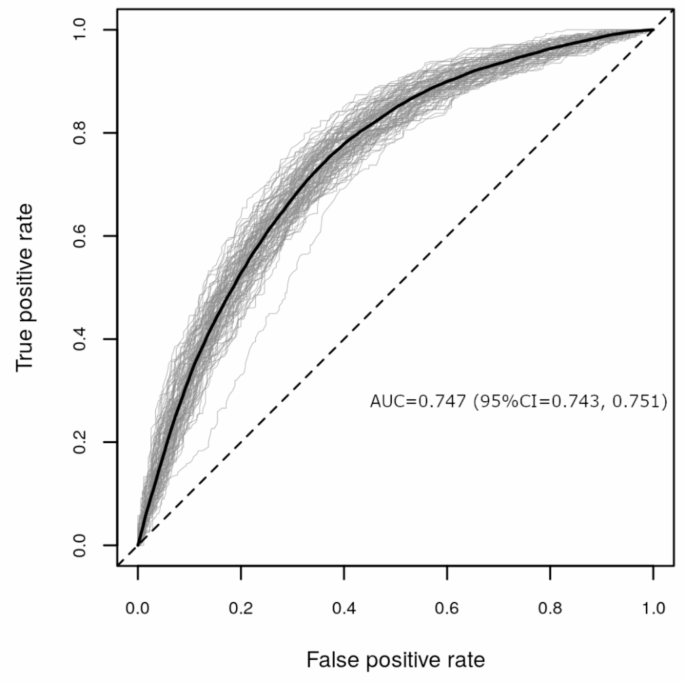
Performance evaluation of NModel = 100 random forest models including as predictors age, sex, 174 metabolites and 148 proteins to classify health status (any morbidity vs. healthy) represented as ROC AUCs. In the plot each validation run is shown as a gray line with the average curve shown in black.
We next selected individual features (i.e., age, sex, metabolites or proteins) based on their importance (as expressed as mean decrease in Gini Index) and computed p-values for each feature’s Gini Index from an empirical background distribution. We selected a feature if it was at least 50 times significant at the level of α = 0.05 and obtained 33 features, including 21 metabolites and 10 proteins, with age being the most important and sex the least relevant for predicting health status (Fig. 4a). Among the top ten omics markers were the metabolites serotonin, glutamate, hexose, three acylcarnitines (C18:1, C16:1, C16), ornithine, and the proteins CFH, A2M and IGFALS. The medication-adjusted abundance distributions of these metabolites and proteins stratified by health status are presented in Fig. 4b. Individuals with any morbidity had lower mean abundance of serotonin, taurine and lysoPC C18:2, and higher mean abundance of all other metabolites. Regarding proteins, individuals with any morbidity had lower mean abundances of A2M, IGFALS, IGHM, and F2, and higher abundance of CFH, C4BPA, A1BG, APOH, AFM, and RBP4.

Evaluation of importance for significant features identified through the random forest models including as predictors age, sex, 174 metabolites and 148 proteins, for health status (any morbidity vs. healthy). #: Rank of the specific feature. Predictor significance was estimated by permutation testing, which generates NModel = 100 background distributions, yielding 100 p-values for each predictor variable. Box plots are color-coded by the number of times a p-value was significant for such a variable (p < 0.05): red, all 100 runs returned a significant p-value; orange, between 80 and 99 runs returned a significant p-value; blue, between 50 and 79 runs returned a significant p-value. Panels are restricted to features that are significant in at least 50% of all runs. Density plots are scaled to have the same width, a median of zero (0) (horizontal bar) and standard deviation of one (1) for the healthy group. For comparability, the any morbidity group data have been scaled to the standard deviation of the healthy group. (a) Mean decrease in Gini Index for significant features. (b) Violin plots presenting scaled abundance distributions stratified by health status for significant features identified through RF, ordered by importance from left to right.
To better characterize the actual association between health status and each significant metabolite and protein from the RF analysis, we performed separate regression analyses with their abundance as the response variable and health status (any morbidity vs. healthy), age and sex as the explanatory variables, allowing us to evaluate the differences in abundances of these markers by health status independently of age or sex. Coefficients for health status were extracted from these models and are presented in Fig. 5 and Supplementary Table S3. In order to account for multiple hypothesis testing, we applied a Bonferroni correction by multiplying the p-values by the number of performed tests (n = 31 metabolites and proteins). Metabolites and proteins were considered relevant if their adjusted p-value was smaller than 0.05 and if the difference in abundance was larger than the data set-specific observed technical variance of that marker (see Methods for details). Individuals with any morbidity had, on average, 22% lower mean abundance of serotonin and 12% higher abundance of serum glutamate. Twelve other markers (C18:1, C16:1, lyso PC a C18:2, PC aa C32:1, tyrosine, taurine, hexose, kynurenine, AFM, CFH, RBP4, and A1BG) passed the multiple-testing correction, however, the observed differences in abundances did fall within the range of the technical variability and were thus not considered significant16. Given that age was the strongest predictor for health status in the RF model, we further investigated and compared the coefficients for age and health association from the regression models. For some markers, such as citrulline, abundances were almost entirely explained by age and the coefficient for the association with health status from the regression model was only very small, and not significant. For others, such as serotonin and glutamate, associations with health status were strong, even in these age-adjusted models, suggesting an age-independent association of these metabolites with health.

Volcano plot for the differential abundance of metabolomic and proteomic markers of health status (any morbidity vs. healthy). Coefficients represent the log2-difference in average concentrations between the groups.
Metabolomic and proteomic signatures related to CIRS domain specific morbidity
We additionally evaluated associations between CIRS organ-specific morbidity and all available metabolites and proteins. To do so, we implemented separate regression models for medication adjusted abundances of all 174 metabolites and 148 proteins as response variable and with each CIRS domain as well as age and sex as explanatory variables, and evaluated whether markers were shared across – or specific for any domain (Fig. 6; Supplementary Table S4). In total, 83 significant omics-disease associations were identified, passing both significance criteria (Bonferroni correction for multiple testing, consideration of technical variability), with 40 metabolites and 17 proteins being significant for ≥ 1 CIRS domain. Associations were observed with the cardiac, vascular, hypertension, endocrine-metabolic, renal, hepatic, psychiatric, neurological, respiratory and lower gastrointestinal and genitourinary domains (Fig. 6). Eleven metabolites (serotonin, glutamate, isoleucine, taurine, dihydroxyphenylalanine, several glycerophospholipids and acylcarnitines) and three proteins (F2, C3, A2M) were shared across multiple domains. For example, serotonin was related to the cardiac, vascular, hypertension and psychiatric systems, and glutamate to the hypertension, endocrine-metabolic, respiratory and hepatic domains. The proteins F2 and A2M were related to the cardiac, vascular, and the renal domains, and C3 to the hypertension and endocrine-metabolic domains. Overall, phosphatidylcholines and sphingolipids were all negatively associated with morbidity conditions in the related CIRS domain, whereas for acylcarnitines positive associations were observed. The directionality of biogenic amines and amino acids was not consistent across classes but remained consistent across CIRS domains. For proteins, negative associations were observed with APOB, APOD, APOM, IGHM, CD5L, PON1, FCN3, F2, C4BPA, IGHG2 and IGKC, whereas positive associations were found with SERPINA1, AFM, VTN, C3, HP, SERPIND1 and A2M. In general, all metabolites and proteins that were significantly associated with multiple domains showed consistent effect directions, being either negative or positive.

Heatmap presenting associations between metabolites, proteins and CIRS organ domains. Associations were obtained from multiple linear regression models adjusted for age and sex. Hierarchical clustering using the Euclidean distance as the similarity measure was applied by clustering rows and columns based on the coefficients describing the associations between metabolites and proteins with each corresponding CIRS organ domain. Only metabolites and proteins that were significantly associated with at least one specific CIRS domain are presented. Asterisks (*) highlight significant associations. β-coefficients are color-coded as follows: red hues represent positive relations and blue hues represent negative relations.
link